
Kernel Pwn 初探
前言
本文不会过多涉略内核的基础知识, 至少不会从基础知识谈起。怀着打开新世界的雀跃, 我们将直接从实战的角度出发, 径直走入kernel pwn的世界。
环境与工具
环境
一道kernel pwn题目, 往往包含以下几个部分:
- 内核模块文件(.ko): 这是题目的核心, 也是一般我们与之交互的对象。.ko(kernel object)与.so(shared object)相对, 在Linux系统中被称作可加载内核模块(LKMs, Loadable Kernel Modules), 在内核启动后, 可以通过”insmod”或”modprobe”命令将模块加载进内核.
当尝试加载模块进内核时, 内核会执行以下操作:- 入口点调用:内核根据模块定义的 module_init(init), 找到对应的init函数并执行。
- 注册接口: 使用register_chrdev或proc_create(filename, …, &fops)等在/dev、/sys或/proc目录下创建一个对应filename的伪文件。而fops(File Operations)是模块与用户程序交互的关键。它是一个结构体, 里面记录了当用户对该文件进行操作(如读写)时所对应的注册函数。之后便可通过对该伪文件的操作来触发对模块中的函数的调用, 如read、write、ioctl等。
- 内核镜像(image): 即之后运行的kernel, 一般会通过qemu仿真, 如’qemu-system-x86_64 -kernel “bzImage”‘命令就会加载bzImage文件作为内核程序启动。内核镜像一般有以下几类:
- vmlinux:原始内核文件, 未经压缩, 可能包含完整的符号表和调试信息, 适合调试使用。但由于体积较大(通常几十MB到几百MB), 不适合直接用作启动内核。
- zImage: 压缩内核镜像, zImage是vmlinux经过gzip压缩后的文件。
- bzImage:bzImage中的bz表示“big zImage”。bzImage不是用bzip2压缩,而是要偏移到一个位置,使用gzip压缩。其中包含了一个小的引导程序(bootsect.S 和 setup.S),用于在启动时解压内核。zImage与bzImage的不同之处在于,zImage 解压缩内核到低内存(第一个 640K),bzImage 解压缩内核到高内存(1M 以上)。如果内核比较小,那么采用 zImage或bzImage 都行,如果比较大应该用bzImage。
- 文件系统(.cpio, .img): 内核启动后, 往往需要一个文件系统来提供用户空间的运行环境。常见的文件系统有initramfs(cpio格式, “copy in, copy out”, 可以通过”cpio -idmv < .cpio”命令解压)和ext4(img格式)等。initramfs通常用于内核启动的初始阶段, 提供必要的工具和库文件。而ext4则是一个完整的文件系统, 可以包含更多的用户程序和数据。此外还有initrd(init ramdisk)等系统格式。
- 启动脚本(.sh): 启动脚本一般包括两种:
- 一种是用于启动内核, 其中包含了cpio创建文件系统、qemu启动内核仿真等一系列操作;
- 另一种一般用于在内核启动后, 执行一系列初始化操作(在qemu的append参数中指定, 如’-append “rdinit=/init’), 如挂载文件系统、安装驱动、启动服务及启动特定程序等。
工具
除一般的pwn工具外, kernel pwn额外常见使用的工具还包括:
- extract-vmlinux: Linux官方脚本工具, 能够从bzImage等提取出vmlinux。直接去github下载脚本文件即可。提取到vmlinux后, 即可通过ida等工具进行静态分析或使用”gdb vmlinux”进行动态调试。
- vmlinux-to-elf: 此工具能从vmlinux/vmlinuz/bzImage/zImage内核映像获取完全可分析的ELF文件,其中包含恢复的函数和变量符号。
- ropper: 用于获取gadget,比ropgadget快。
运行与调试
内核调试一般使用qemu+gdb的方式进行。因为qemu内置了gdbserver, 启动qemu时, 通过”-s”(为”-gdb tcp::1234”的缩写)参数即可开启gdbserver(1234端口, 额外使用”-S”参数还可暂停CPU), 然后在宿主机上使用”gdb vmlinux”命令加载内核符号表, 再通过”target remote :1234”连接到qemu的gdbserver。还可以使用”add-symbol-file [file] [address]”命令加载内核或模块的符号表。其中file为解压后带符号的vmlinux或模块文件, address为模块加载到内核的实际地址, 内核地址一般通过如下方法获得:
- dmesg命令: 内核日志中会打印模块加载信息, 包括模块加载地址。
- /proc/kallsyms文件: 该文件包含内核的所有符号表, 可以通过查找符号名获取其加载地址。
- /proc/modules文件: 该文件包含已加载模块的信息, 包括模块名、大小、加载地址等。
- /sys/module/[module_name]/sections/目录: 该目录下包含模块的各个段(section)的地址信息。
- kallsyms_lookup_name函数: 该函数可以在内核空间中查找符号的地址, 但需要在内核模块中调用。
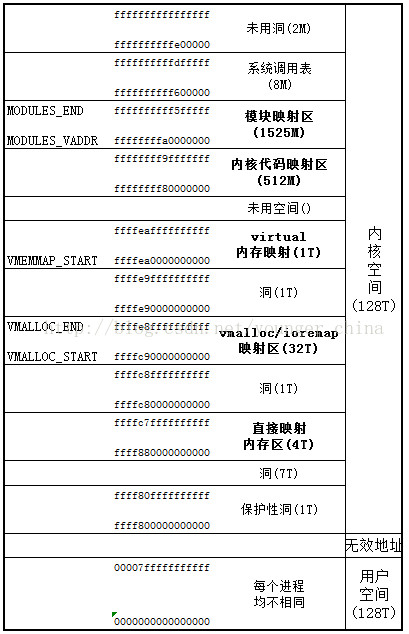
对于内核态地址, 还需要注意的一点是内存分布问题, 在不开启KASLR(通过在内核启动参数中添加”nokaslr”)的情况下, 内核一般会被加载到一个固定的高地址(如0xffffffff81000000), 而模块则会被加载到另一个固定的高地址(如0xffffffffc0000000)附近。此外, 现代linux内核还会存在一个直接映射区: 内核会将物理内存的全部平铺在一个连续的虚拟地址空间中(一般为0xffff880000000000开始), 以便内核能够高效地访问物理内存。
除直接映射区的虚拟地址外, 其他内核地址都需要通过页表映射才能找到真正的物理地址, 以使用四级页表为例, 找到进程的task_struct后, 拿出mm_struct, 从中取出PGD(Page Global Directory, 全局页目录), 然后遍历四级页表: PGD(Page Global Directory)、PUD(Page Upper Directory)、PMD(Page Middle Directory)和PT(Page Table), 找到虚拟地址对应的物理地址。
对于访问其他进程的数据, 一般有两种方式:
- 一是上面提到的先通过页表转换拿到物理地址, 然后通过对物理地址加上直接映射区的起始地址掩码, 便可直接在当前进程中访问其中的数据。
- 二是不拿物理地址, 在拿到PGD后, 直接将当前进程的页表寄存器CR3切换为该全局页目录(注意PGD里面存放的是虚拟地址, 需要先转换为物理地址(CR3中保存的是全局页目录的物理地址), 然后加上低3十六进制位的标志位), 这样就可以直接在当前进程的内核态访问子进程数据了(注意内核态直接访问用户态数据需要关闭SMAP(Supervisor Mode Access Prevention)保护, 通过查看CR4寄存器的第20位检查是否开启, 若开启了则需要通过stac指令关闭)。
开启KASLR后, 以上加载地址会随机化, 但仍然会保持在高地址范围内。
基础利用方式
在内核态利用, 已经没有libc函数或者syscall可以用了, 能用的只有/proc/kallsyms中的内核函数。就利用手法而言, 目前总结为以下几种:
- 提权: 通过调用内核中的”prepare_kernel_cred”和”commit_creds”函数, 将当前进程的权限提升为root。一般的利用流程为:
- 调用”prepare_kernel_cred(0)”函数, 获取一个新的credentials结构体指针, 该结构体的各个字段均被初始化为0, 表示最高权限。
- 调用”commit_creds”函数, 将当前进程的credentials结构体替换为刚刚获取的高权限结构体。
- 由于提升的是当前进程的权限, 因此在利用完成后, 还需要返回用户态, 去进行进一步的操作。
- orw: 内核态的orw可以通过以下内核函数进行, 这里需要注意的是, 即使驱动可以在内核以0优先级执行任意代码, 但其实际代表的用户权限仍是进入内核前的用户。而对于文件访问来说, 仍会检查用户是否具有读写权限, 否则就会open失败。
- filp_open(filename, flags, mode): 打开一个文件, 返回一个file结构体指针。
- kernel_read(file, buf, len, offset): 从file结构体指向的文件中读取数据到buf缓冲区。
- printk(buf): 将buf缓冲区的数据写入到内核日志文件中。之后便可以通过”dmesg”命令查看日志内容。
- 命令执行: 通过”run_cmd”函数, 该函数可以执行一条cmd命令, 但无法返回输出结果。
其他
内核加载驱动是典型的“运行时链接(Runtime Linking)”, 内核的主体在开机时已经占据了一块连续的虚拟地址空间, 驱动(LKM, loadable kernel module)加载时, 内核并不会修改原本的代码段和数据段, 而是通过内核分配器(通常是 vmalloc)在内核的“模块区域(Module Mapping Area)”开辟一块新的空间。然后根据.ko文件的需求, 申请不同权限(如.text RX, .data RW等)的内存页。
运行时链接仍然需要完成链接过程的两个基本任务: 符号解析与重定位。如加载器会查询内核的全局符号表(System.map), 把需要重定位的符号的真实地址填入驱动的代码段中。
一旦加载完成, 从 CPU 的视角来看, 驱动的数据段和内核原本的数据段地位是平等的。内核和所有驱动都运行在同一个内核地址空间(通常是高地址), 并且它们的特权级一致: 运行在 Ring 0。
正如之前提到的, /proc不同于普通的文件系统, 它是特殊的procfs, 不存在于磁盘, 而仅存在与内存中, 由内核遍历task_struct动态生成。一切对其及其子目录的文件操作都会被内核拦截, 转而去调用对应注册的file->f_op->op_func。
在内核与用户空间进行数据交换时, 一般使用的都是”copy_from_user”和”copy_to_user”, 与普通的”memcpy”不同的是, 这两个函数会对地址进行额外的范围检查(确保地址确实属于该用户空间)、权限检测以及异常处理。
在内核模块动态申请内存时, 一般使用”kmalloc”和”vmalloc”。其中”kmalloc”分配的是连续的物理内存, 适合分配小块内存(通常小于等于几百KB), 并且分配效率较高, 最终返回的是位于直接映射区的虚拟地址。而”vmalloc”则分配的是非连续的物理内存, 但在虚拟地址空间中是连续的, 适合分配大块内存(通常大于几百KB), 但分配效率较低, 最终返回的是位于vmalloc映射区的虚拟地址。