
heap
ptmalloc2
ptmalloc2是现代Linux系统中glibc默认的内存分配器,基于Doug Lea的malloc(dlmalloc),在此基础上添加POSIX线程支持的多线程版(POSIX Thread Malloc)。
ptmalloc2的核心逻辑几乎全部集中在malloc()和free()两个函数的实现中(glibc/malloc/malloc.c),其他内存分配函数如realloc()、calloc()(分配n个连续的堆块并对内存进行清零)等都只是在这两者的基础上的封装。
在ptmalloc2中,堆内存的组织结构为chunk和bin:
chunk:块是实际分配的内存单元,每次malloc都对应一个chunk。每个chunk包含元数据和用户数据两部分,元数据存储在chunk的前面,用于管理chunk的状态和大小等信息,大小为16字节(64位系统)。bin: 桶是相同大小chunk的分类链表,用于快速重用空闲块。unsorted bin: 只有一个bin双向链表,对应bins索引1,里面的chunk没有进行排序。small bins: 共62个,对应bins索引2~63,存储[32B, 1024B)大小chunk的双向链表,同一个small bin链表中的chunk的大小相同。large bins: 共63个, 每(32, 16, 8, 4, 2, 1)个组成一类,每类中的chunk大小的上下界区间大小相同,存储大块(>1024字节)的双向链表,对应bins索引64~126。fast bins: 共10个,单独由fastbinsY变量指定而不与上面三种bin位于bins中。存储小块(0x20-0xb0)的单向链表,分配和释放速度快,fastbin容器中的chunk的INUSE标志位总是被置位,因此不会进行合并操作,容易产生碎片。tcache: 线程缓存,共64个,由tcache_perthread_struct结构体管理,存储小块32B, 1040B的链表,提升多线程环境下的分配效率。top chunk: 未分配的堆顶部分,当bin中找不到合适的块时,会从top chunk中切割新的chunk。
arena(malloc_state结构体)是ptmalloc2中用于管理堆内存的堆管理器实例,每个arena有各自的互斥锁、bins和top chunk等。在单线程环境下,所有的内存分配请求都由主arena处理;而在多线程环境下,每个线程会有自己的arena,以减少锁竞争,提高并发性能。其中主线程的arena会通过brk()(直接mmap()出的堆块不会放到arena管理)扩展主堆区,内存布局连贯; 而其他线程的arena只能通过mmap()分配或拓展出独立的内存区域,然后将其作为一个新堆块通过heap_info链表链接起来放入arena中管理。
引入arena机制使得不同线程间可以自行管理自己的堆内存(线程安全的),malloc分配的堆块属于某个特定的arena,但分配后的chunk仍然可以跨线程访问或释放,这就是为什么说堆是线程间共享的。而栈是进程间独立的, 除主线程外,其他线程的栈在调用pthread_create()时由glibc分配(通常通过mmap()申请一段匿名内存, [stack:tid]),不同线程的栈互不干扰,若一个线程越界访问另一个线程的栈,会触发段错误。
free(ptr)
- 从chunk的元数据中读取
size与prev_inuse标志。 - 如果size在
tcache区间中且对应tcache未满:- 将chunk放到该
tcache的链表头(entry->next = tcache->entries[idx];entries[idx] = entry),增加counts[idx]。
- 将chunk放到该
- 如果chunk的
M标志位被置位(表示该chunk是通过mmap()分配的),则直接调用munmap()释放该chunk。 - 若size不属于
tcache区间或对应tcache已满,进入arena级处理:- 若chunk大小属于
fastbin大小范围:- 将 p 以 LIFO 方式插入 fastbinsY[fastbin_index](把 p->fd 指向原 head,头指针设为 p)。fastbin 不立即合并,也不设置 fd/bk 成双向结构。但会在free一个超过阈值(64KB)或某次malloc chunk(进入unsorted bin检查)时触发
malloc_consolidate(),将fastbin中所有的chunk逐个取出并与相邻free chunk合并,再把合并结果放到unsorted bin, 从而避免长期碎片化。
- 将 p 以 LIFO 方式插入 fastbinsY[fastbin_index](把 p->fd 指向原 head,头指针设为 p)。fastbin 不立即合并,也不设置 fd/bk 成双向结构。但会在free一个超过阈值(64KB)或某次malloc chunk(进入unsorted bin检查)时触发
- 否则(非 fastbin)尝试向前/向后合并(coalesce), 并将最终的chunk放入
unsorted bin或top chunk:- 若
prev_inuse== 0(前一个chunk是free),则找到前块合并:将prev_size+size形成新大小,并把p指向prev(向后合并/“backward merge”) - 若后一个chunk是free(通过读取再下一个chunk的header判断),则找到后块合并:将
size+下一个chunk的size形成新大小,并从bin中移除后块(向前合并/“forward merge”)。 - 若后面的chunk是
top chunk,则直接合并进top chunk并更新arena的top chunk指针。
- 若
- 若chunk大小属于
malloc(size)
- 将请求的size规范化为内存管理的chunk size(16字节对齐/8字节overlap + header大小,得到真正size)。
- 首先检查
tcache(线程私有):- 计算tcache bin index;如果 tcache->entries[idx]非空, 直接弹出链表头并返回对应用户地址(不触及arena结构,也不会做合并)
- 如果size很大(>128 KB), 直接调用
mmap()分配一个独立的chunk返回。 - 否则获取
arena heap lock, 检查arena:- 检查
fast bins:- 若size在fastbins范围且对应bin非空,弹出头部返回(LIFO)。
- 检查
small bins:- 当size匹配某个small bin的size-class时,从small bin的末尾取出chunk。
- 否则:
- 针对更大的chunk,并不会直接在large bin中去找有无合适的chunk, 而是先调用
malloc_consolidate()函数去处理fast bins中的chunk,将所有的chunk合并后(或直接)放入unsorted bin中。然后才去处理unsorted bin和large bins:- 首先按照
FIFO的顺序遍历unsorted bin, 如果满足条件直接返回, 否则将其放入对应的small/large bins中。 - 然后在
large bins中查找合适的chunk:- 通过计算
large bin index定位到对应bin, 遍历该bin链表寻找第一个满足条件的chunk。 - 若未找到恰好合适的chunk, 则找到第一个不小于所需chunk大小的chunk, 将其分割后返回, 剩余部分放到
unsorted bin中。
- 通过计算
- 首先按照
- 针对更大的chunk,并不会直接在large bin中去找有无合适的chunk, 而是先调用
- 检查
- 若arena中仍未找到满足条件的chunk, 检查
top chunk:- 若top chunk大小足够,从top chunk头部拆分出一段返回分配结果。
- 若top chunk大小不足,通过系统调用拓展堆空间:
- 调用sbrk/mmap以从内核获取更多内存用于创建更大的top chunk,或直接创建一个mmapped chunk。
最后再介绍一下几个linux内存管理相关的系统调用:
brk(addr):set program break,设置程序堆顶位置为addr,用于绝对扩展或收缩堆空间。成功时返回0,失败时返回-1。sbrk(N):set break relative,将堆顶位置增加或减少N个字节,用于相对扩展或收缩堆空间。成功时返回调用前的堆顶地址,因此常通过sbrk(0)获取当前堆顶地址。mmap(addr, length, prot, flags, fd, offset):用于匿名分配大块内存或将文件/设备映射到内存中,返回映射区域的起始地址且会将内存清零。对于ptmalloc2中的malloc()函数来说,小块内存通常使用brk()/sbrk()扩展主堆区(main arena),而大块内存(>128 KB)则直接使用mmap()分配独立区域(匿名映射)。munmap(addr, length):释放之前通过mmap()映射的内存区域。mprotect(addr, len, prot):更改内存区域的保护属性,如读、写、执行权限。
chunk
无论一个chunk的大小、所属bins如何,它们都使用一个统一的结构: struct malloc_chunk。但是根据是处于分配状态还是释放状态,它们的表现形式会有所不同:
/* |
在64位系统中, chunk最小为32字节(16字节header + 16字节最小对齐用户数据)。所有chunk大小均为16字节对齐,当申请的chunk size的十六进制表示最低位为小于8时, 由于可以复用下一chunk的header中的prev_size字段存储用户数据(即overlap), 因此实际分配的chunk size会向上对齐。当申请的chunk size十六进制表示最低位大于8时, 则需要额外向下对齐填充。
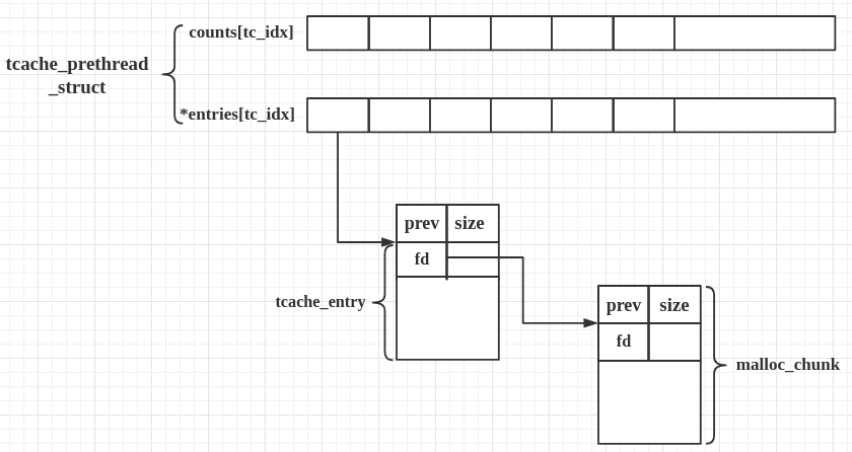
对于arena中的chunk, 它们的fd和bk字段指向上一个和下一个(非物理相邻)的空闲chunk的元数据起始地址, 用于将chunk链接到对应的bin链表中; 而对于tcache中的chunk, fd字段变成了next指针, 指向下一个chunk的用户数据起始地址, bk字段在libc 2.28后变成了key字段, 用于防止double-free攻击。
arena
对于不同系统,arena 数量的约束如下:
- 32位系统:最多支持2*cores个arena
- 64位系统:最多支持8*cores个arena
因此并不是每个线程都会有自己的arena, 当线程数量超过arena数量时, 多个线程会共享同一个arena。
malloc_state是arena的核心数据结构, 记录了每个arena当前申请的内存的具体状态。无论是thread arena还是main arena, 它们都有且只有一个malloc_state结构体。其中main arena的malloc_state并不在heap中,而是一个全局变量,存放在libc.so的数据段。
struct malloc_state { |
其中mfastbinptr和mchunkptr均是指向malloc_chunk结构体的指针类型。fastbinsY数组存储了10个fast bin链表的头指针; bins数组存储了所有unsorted bin、small bins和large bins的链表头指针(每个bin使用两个指针表示双向链表的头和尾); top指针指向当前arena的top chunk。
tcache
tcache是glibc 2.26(ubuntu 17.10)之后引入的一种技术, 目的是提升堆管理的性能。但提升性能的同时舍弃了很多安全检查,也因此有了很多新的利用方式。
tcache引入了两个新的结构体,tcache_perthread_struct和tcache_entry。每个线程都会维护一个tcache_perthread_struct,存放在当前线程申请的第一个堆块中(0x290B), 它是整个tcache的管理结构,一共有TCACHE_MAX_BINS个计数器和TCACHE_MAX_BINS项tcache_entry,其中:
counts记录了tcache_entry链上空闲chunk的数目,每条链上最多可以有7个chunk。entries指针用单向链表的方式链接了相同大小的处于空闲状态的chunk的用户数据起始地址。
|
tcache_perthread_struct结构体的地址存放在TLS(Thread Local Storage)中,而glibc的数据段中的struct malloc_par结构体类型的mp_变量中也保存着部分与tcache相关的定义:
struct malloc_par { |
glibc heap高版本安全演变
glibc 2.26
- 引入
tcache,提升多线程环境下的堆分配性能。
glibc 2.28
- 在
tcache_entry中引入key字段,每次free时会检查该字段以防止double-free攻击。
glibc 2.31
- 将
tcache_perthread_struct中的counts字段从char改为uint16_t。 - 增加了malloc时对
counts[idx] > 0的检查。
glibc 2.32
- 引入
safe-linking机制,对单链表结构的fast bins的fd指针和tcache_entry的next指针进行加密,不再直接存储下一个chunk地址,而是存储(pos >> 12) ^ ptr的结果,其中pos代表next指针的地址,而ptr代表该next指针想指向的下一个chunk的地址。
glibc 2.34
- key的值从tcache_perthread_struct变成了一个随机数。